Python生态杂草众生,我们该如何选择
互联网大数据处理技术与应用 2018-08-06 20:21
Python一举超过Java,吸引了众多开发人员。但Python生态过于活跃,导致了这样的结果,即一个功能有很多种实现方法库可选择。在Web信息抽取、机器学习、数据挖掘、深度学习等领域的python库中,这个现象更加明显。对于具有选择困难症的人来说,面对如此之多的开发库往往难于做出合适的决定,大都情况下只能跟随大众。
然而,活跃的生态总是会杂草众生,跟随大众随便摘一个果子吃也许并不是最好的选择。因此很有必要深入了解各种开发库的技术原理,并分析其优劣,这里就以Web信息抽取为例。
Web信息提取包含Web页面中的超链接提取和Web内容提取两大部分,都是网络爬虫技术的重要组成部分。前者是找出页面中的所有超链接或符号一定规则的超链接,作为爬虫的爬行任务,在技术实现上比较简单。后者是从Web页面中提取信息内容,一般是指页面中有意义的内容,相应的提取技术实现上比较复杂。
目前,在Python中已经有很多种开源库可以用于实现基于HTML结构的信息提取。这些开源库完成了HTML的逻辑树构建,并给开发人员提供了丰富的搜索策略,可以灵活方便地实现Web信息提取。这些开源库主要有html.parser、lxml、html5lib、BeautifulSoup以及PyQuery等等。
然而这些库所依赖的基础树并不相同,HTML的逻辑树主要有dom、minidom、lxml.etree。基于这些树的5个解析器之间也存在一定的依赖关系,如图。最终这些库提供给Py开发人员的编程方式有:事件驱动、xpath、jquery等。
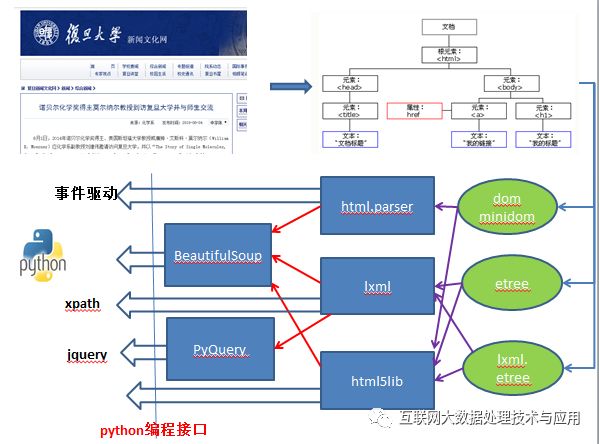
其中,BeautifulSoup可以集成html.parser、lxml、html5lib三种解析器,使它变得很流行。它通过调用其它开发库,而实际上只是优化了编程接口, BeautifulSoup的这种做法意在通过吃小鱼而让自己成为大鱼,也有些像俄罗斯的套娃。一层一层,这种二次封装必然带来性能的损伤,最终的选择就取决于你对算法性能和开发方便性的平衡要求了。
作者编著的《互联网大数据处理技术与应用》专著(清华大学出版社,2017)、同名公众号,专注于大数据技术的相关科学和工程知识传播,同时也为读者提供一些拓展阅读材料。关注后可阅读以前推送的原创文章。欢迎选用本书做大数据相关的教材,有相关教学资源共享。
相关标签: 贵阳网站建设 ,贵州网站建设 ,贵阳网站优化 ,贵阳网络公司 ,
- 上一篇:谷歌云APP引擎今天开始支持Python 3.7 2018/8/9
- 下一篇:2018年8 月全球数据库排行榜:Oracle 飙涨,DB2 2018/8/8


